This week-end, many people have started reporting the same issue in Google's Webmaster Forum: no more daily search queries information updates. For most, the data reporting stopped on September 23, 2013, but I have observed this since September 22, 2013.
Yesterday, a top contributor has announced that this issue had been "escalated to the appropriate Google engineers". He mentions this issue started on September 21st. Therefore, it has been 9 days before someone could confirm that Google is aware of it. Google Webmaster Tools (GWT) is known to lag 2 or 3 days behind when it comes to search query data, which explains why most webmasters only started to ask questions at the end of last week. This issue made the headline of Search Engine Roundtable too.
In the confirmation post, a link to a 2010 video has been posted. Matt Cutts discusses which types of webmaster tools errors should be reported to Google. He mentions that Google engineers are a bit touchy when they are asked whether they monitor their systems. So did Google knew about this issue since September 21st and deliberately decided not to answer posts in the Webmaster Tools forum for 9 days or did they just miss it, because it was not monitored?
Many people have been hit by the recent Panda updates. August 21st, September 4th and more recent dates have triggered a lot comments in forums. Many websites lost all their traffic without any explanation. No message in GWT, no manual penalty, nothing. Some of these sites were using plain white hat SEO. Webmasters working hard to produce quality content need GWT search query data feedback, especially when they believe some of their sites have been hit by recent updates. It helps them find out whether they have implemented the proper corrections or not.
On September 11th, a new Matt Cutts video was posted about finding out whether one has been hit or not by Panda, and whether one has recovered from it or not. Unfortunately, it does not contain clear cut information answering the question. This video only confirms that Panda is now integrated into indexing and that one should focus on creating quality content. Google's interpretation of quality content is still vague, yet they have implemented algorithms to sort web pages.
If there is a bug impacting customers using their service, why isn't Google officially open and communicative about it? This has been an ongoing complaining from webmasters. I can understand that Google does not want to give too much information about their systems. They don't want hackers too exploit these against them. However, it clearly seems that the focus is more on not communicating with hackers than communicating openly with regular webmasters. Is Google on the defensive mode?
Google is capable of algorithmically detecting when a website (or some part of a website) has quality issues. It does not hesitate to penalize such websites. Then, why doesn't Google communicate automatically about these issues to regular webmasters in GWT? It is algorithmically possible and scalable too. Google is not the only party interested in creating quality websites. It is in the interest of regular webmasters too. Of course, hackers would try to exploit this information, but overall, if regular webmasters had this information too, they would create better content than hackers too. Users would still sort between good and bad websites, not only Panda.
Sometimes, it really seems like Google does not truly want to collaborate with regular webmasters. I notice selective listening followed by monologues. Ask me questions and I'll answer them. I won't acknowledge any flaws, but I'll secretly work on these so you can't poke me again. This is not a collaborative dialogue, it is a defensive attitude. I believe that acting with excessive caution directly hampers the achievement of one's own objectives.
My strong opinion is that if Google solved this communication issue, it would bring much more return than any other stream of tweaks to their Panda algorithm. Give people the information they need to do a good job, empower them, trust them. Right now, the level of frustration is pretty high in the webmaster community. Frustration leads to lack of motivation. Lack of motivation decreases productivity. No productivity means not a chance to see new quality content or improvements.
There is a needless vicious circle and Google can do something about it, for its own good too.
Showing posts with label Google Webmaster Tools. Show all posts
Showing posts with label Google Webmaster Tools. Show all posts
Tuesday, 1 October 2013
Friday, 8 March 2013
Exiting From Google's Sandbox In A Week
Sharing the experience acquired while trying to get a keyword-stuffed site out of Google's sandbox. I explain how I succeeded faster than methods described on the net so far. Not a silver bullet, but surely a boost. In less than a week, I got my site at search result position number 3 for its title keywords:
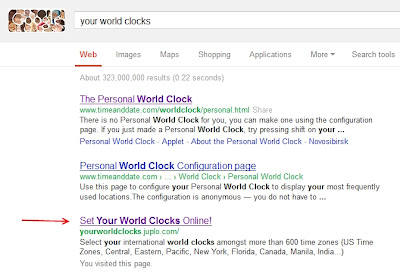
As a reminder, the Google Sandbox effect is observed when a site is indexed by Google, but it does not rank well or at all for keywords it should rank for. The site: command returns pages of your website, proving it is indexed and not banned, but its pages do not appear in search results.
Google denies there is a sandbox where it would park some sites, but it acknowledges there is something in its algorithms which produces a sandbox effect for sites considered as spam. My site would qualify as spam since it was keyword stuffed.
I had registered my site URL in Google Webmaster Tools (GWT) and noticed little to no activity. No indexing of pages and keywords. Fetch as Google would not help. I saw a spike in Crawl Stats for a couple of days, then it fell flat. The site would get no queries, yet the site: command returned its main page.
So, I cleared my site from everything considered spam. I used to following online tools to find my mistakes:
I used Fetch as Google in GWT again, but it did not help get it out of the Sandbox effect. I read all the posts I could find on the net about this topic. Basically, everyone recommends using white hat SEO techniques (more quality content, quality backlinks, etc...) in order to increase the likelihood Google bots will crawl your site again: "It could take months before you get out of the sandbox...!!!"
Not true. I have found a way which showed some results in less than a week. My site is now ranked at the 3rd search result position for its niche keyword. I can see my 'carefully selected' keywords in GWT's Content Keywords page.
So, here is the procedure:
I suspect this method works better than everything suggested so far, because Google bots crawl robots.txt frequently. The sitemap is revisited more often and therefore, Google knows faster that pages have been updated. Hence, it re-crawls them faster, which increase the likelihood of proper re-indexing. No need to wait months for bots to come back. It eliminates the chicken and egg issue.
I don't think this method would work with sites which got penalized because of one bought fake backlinks or traffic. I think shaking those bad links and traffic away would be a prerequisite too. If this can't be achieved, some have suggested using a new URL. I have never tried this, because I never bought links and traffics, but I am reckon this would be part of the solution.
Why did I keyword-stuffed my site in the first place? Because, I was frustrated by GWT which would not show relevant indexing data fast enough for new sites, even when clean SEO was applied. Moreover, GWT does not tell when a site falls into the sandbox effect. Google gives you the silent treatment. This is a recipe for disaster when it comes to creating a trusting and educated relationship with publishers.
Not everyone is a evil hacker!

As a reminder, the Google Sandbox effect is observed when a site is indexed by Google, but it does not rank well or at all for keywords it should rank for. The site: command returns pages of your website, proving it is indexed and not banned, but its pages do not appear in search results.
Google denies there is a sandbox where it would park some sites, but it acknowledges there is something in its algorithms which produces a sandbox effect for sites considered as spam. My site would qualify as spam since it was keyword stuffed.
I had registered my site URL in Google Webmaster Tools (GWT) and noticed little to no activity. No indexing of pages and keywords. Fetch as Google would not help. I saw a spike in Crawl Stats for a couple of days, then it fell flat. The site would get no queries, yet the site: command returned its main page.
So, I cleared my site from everything considered spam. I used to following online tools to find my mistakes:
- http://tool.motoricerca.info/spam-detector/
- http://www.seoworkers.com/tools/report.html
- http://www.google.com/safebrowsing/diagnostic?site=<your-site-url-here>
- http://try.powermapper.com/demo/sortsite.aspx
I used Fetch as Google in GWT again, but it did not help get it out of the Sandbox effect. I read all the posts I could find on the net about this topic. Basically, everyone recommends using white hat SEO techniques (more quality content, quality backlinks, etc...) in order to increase the likelihood Google bots will crawl your site again: "It could take months before you get out of the sandbox...!!!"
Not true. I have found a way which showed some results in less than a week. My site is now ranked at the 3rd search result position for its niche keyword. I can see my 'carefully selected' keywords in GWT's Content Keywords page.
So, here is the procedure:
- The first step is indeed to clear any spam and bad SEO practices from your site. It is a prerequisite. The following does not work if you don't perform this step with integrity.
- Next, make sure your site has a sitemap.xml and a robots.txt file. Make sure the sitemap is complete enough (i.e., it lists all your site's pages or at least the most important ones).
- Then, register your sitemap.xml in your robots.txt. You can submit your sitemap.xml to GWT, but it is not mandatory.
- Use Fetch as Google to pull your robots.txt in GWT and submit the URL. This makes sure your robots.txt is reachable by Google. It avoids loosing time.
- Make sure there is a <lastmod> tag for each page in your sitemap, and make sure you update it to a recent date when you have updated a page. This is especially important if your page contained spam! Keep updating this tag each time you modify a page.
- If you don't cheat with the <lastmod> tag, I have noticed Google responds well to it.
- Wait for about a week to see unfolding results.
- It is as simple as that. No need for expensive SEO consulting!
I suspect this method works better than everything suggested so far, because Google bots crawl robots.txt frequently. The sitemap is revisited more often and therefore, Google knows faster that pages have been updated. Hence, it re-crawls them faster, which increase the likelihood of proper re-indexing. No need to wait months for bots to come back. It eliminates the chicken and egg issue.
I don't think this method would work with sites which got penalized because of one bought fake backlinks or traffic. I think shaking those bad links and traffic away would be a prerequisite too. If this can't be achieved, some have suggested using a new URL. I have never tried this, because I never bought links and traffics, but I am reckon this would be part of the solution.
Why did I keyword-stuffed my site in the first place? Because, I was frustrated by GWT which would not show relevant indexing data fast enough for new sites, even when clean SEO was applied. Moreover, GWT does not tell when a site falls into the sandbox effect. Google gives you the silent treatment. This is a recipe for disaster when it comes to creating a trusting and educated relationship with publishers.
Not everyone is a evil hacker!
Thursday, 14 February 2013
Dealing With Google Webmaster Tools Frustrations
If you don't understand the mechanics behind Google Webmaster Tool (GWT, not to be confused with Google's Web-Toolkit framework) and of page indexing, trying to obtain valid information about your website can be a very frustrating experience, especially if it is a new website. This has even led me to take counter-productive actions in order to solve some of GWT flaws. This post is about sharing some experience and tips.
First, you need to know that GWT is a very slow tool. It will take days, if not weeks to produce correct results and information, unless your website is very popular and already well indexed. Secondly, GWT is obviously aggregating information from multiple Google systems. Each system is producing its own information and if you compare all this information, it is not always coherent. Some of it is outdated or plain out-of-sync.
I have noticed that Google gives extra premature exposure to new websites to test their success, before letting them float naturally. It also tries to find out how often your pages are updated. With a new website under construction, not only will you fail the premature exposure because there is no valuable content for users, but if there are weeks before you put the first final version of your site online, Google may decide not to come back to your site for weeks too, even if new content is uploaded in the mean time (pretty frustrating). Of course, you can use GWT's Fetch as Google feature, but there is no guarantee it will accelerate the process (at least this is what I observed).
Nowadays, I don't register my websites in GWT prematurely. I wait until a first final version is available for production. Next, I apply all the relevant white hat SEO tricks. Then, I create a proper sitemap and robots.txt. At least, after having uploaded everything in production, I register and submit everything to GWT and monitor the indexation process with GWT's crawl stats, together with the site: and cache: commands, until GWT starts to display coherent data. It has eliminated a lot of frustration and teeth grinding!
First, you need to know that GWT is a very slow tool. It will take days, if not weeks to produce correct results and information, unless your website is very popular and already well indexed. Secondly, GWT is obviously aggregating information from multiple Google systems. Each system is producing its own information and if you compare all this information, it is not always coherent. Some of it is outdated or plain out-of-sync.
Understanding The Indexing Process
- Crawling - The first step is having Google's bots crawl your page. It is a required step before indexation. Once a page is crawled, the snapshot is stored in Google's cache. It is analyzed later for indexing by another process.
- Indexing - Once a page has been crawled, Google may decide to index it or not. You have no direct influence on this process. The delay can vary according to websites. Once indexed, a page is automatically available in search results (says w3d).
- Ranking - An indexed page always has a ranking, unless the corresponding website is penalized. In this case, it can be removed from the index.
- Caching - It is a service where Google stores copies of your pages. Google confirms it is the cached version of your page which is used for indexing.
- The page falls under bad SEO practices, which includes keyword stuffing, keyword dilution, duplicate content, or low quality content.
- The page is made unreachable in your robots.txt.
- There is no URL link to your page and it does not appear in any sitemap known to Google.
Is My Page Indexed?
Here is a little procedure to follow:- The site: command
- Start by running the site: command against the URL of your page (with and without the www. prefix). If it returns your page, then it is indexed for sure. If not, it does not mean your page has not been indexed or that it won't be indexed soon. The site: command provides an estimation of indexed pages.
- You can use the site: command against the URL of your website to have an estimation of the pages Google has indexed for your site.
- The cached: command
- If the site: command has returned your page, then the cached: command will tell you which version (i.e. snapshot) it has used (or will soon use) for indexing (or reindexing). Remember there is a delay between crawling/caching and indexing.
- Else, if it returned nothing and the cached: command returned a snapshot of your page, it means Google bots have managed to crawl your page. This means indexing may or may not happen soon, depending on Google's decision.
- If the cached: command still does not return your page after a couple of days or weeks, then it may indicate that you don't have a clean page.
What Can I Do About It?
Here is another procedure:- No confirmation that your page has been crawled
- The first step is to make sure your page's URL is part of a sitemap submitted to Google (eventually using GWT for submission). Don't believe that Google will naturally and quickly find your page for crawling, even if it is backlinked.
- Double-check that your page's URL is not blocked by your robots.txt.
- Add a link to your sitemap in your robots.txt.
- Avoid using the GWT's Fetch As Google feature as Google will penalize excessive use with less frequent visits to your site. It does not accelerate the indexing process. It just notifies Google it should check for new/updated content. Google can be a pacha taking its time.
- Always prefer submitting a complete and updated sitemap versus using GWT's Fetch As Google feature. You don't need to resubmit a sitemap if its URL is defined in your robots.txt. Search engines revisit robots.txt from time to time.
- Take a look at GWT's crawl stats. It will tell you (with a 2-3 days delay) whether Google bots are processing your site.
- Double-check that your page is not suffering from bad SEO practices. Such pages can be excluded from the indexing process.
- Be patient, it can take days, and sometimes weeks before Google reacts to your page.
- Check GWT's index status page, but never forget it reacts very very slowly to changes. If you are in a hurry, you may obtain faster information by running the site: and cache: commands from time to time.
- Your page is in the cache, but no confirmation of indexation
- Double-check that your page is not suffering from bad SEO practices. Such pages can be excluded from Google's index.
- If your site contains thousands of pages, Google will often start by indexing only a subset. Typically, it will be those it thinks have a better chance of matching users' search requests. If your page is not part of them, check whether other pages of your site are indexed using your website URL in the site: command.
- If, after being patient, your clean page is still not being indexed, then it probably means Google does not find it interesting enough. You need to improve its content first. Next, try to apply more white hat SEO recommendations. Layout design, readability and navigability are often the culprit when content isn't.
- Your page is in the index, but does not rank well
- Double-check that your page is not suffering from bad SEO practices. Such pages can be included in Google Index with a low ranking.
- Make sure you are using proper keywords on your page, title and meta description. Perform the traditional white hat SEO optimization tricks. If you got everything right and still don't get traffic, it means users don't find your content interesting or their is too much competition for what your offer.
About New Websites & Under Construction
Because of the slowness of GWT and a lack of understading of its mechanics, I once tried to accelerate the indexing of new websites by first submitting 'under construction' versions, stuffed with relevant keywords. It did not help at all! Not only Google did not index my sites (or with a very bad ranking), once I uploaded the final version a couple of weeks later, Google took weeks to (re)index them properly. Google's cache was soooo out of sync...I have noticed that Google gives extra premature exposure to new websites to test their success, before letting them float naturally. It also tries to find out how often your pages are updated. With a new website under construction, not only will you fail the premature exposure because there is no valuable content for users, but if there are weeks before you put the first final version of your site online, Google may decide not to come back to your site for weeks too, even if new content is uploaded in the mean time (pretty frustrating). Of course, you can use GWT's Fetch as Google feature, but there is no guarantee it will accelerate the process (at least this is what I observed).
Nowadays, I don't register my websites in GWT prematurely. I wait until a first final version is available for production. Next, I apply all the relevant white hat SEO tricks. Then, I create a proper sitemap and robots.txt. At least, after having uploaded everything in production, I register and submit everything to GWT and monitor the indexation process with GWT's crawl stats, together with the site: and cache: commands, until GWT starts to display coherent data. It has eliminated a lot of frustration and teeth grinding!
Subscribe to:
Posts (Atom)